We start our Knowledge Discovery Journey on Cloud Computing with a few simple steps. The first step to find some of the Cloud Computing Terms. It is very easy for humans to just look at a document and quickly identify relevant terms. However, it assumes that you have some knowledge of the topic. Since we want to automate this process as much as possible, we will use some simple tools.
- The first tool is Google Search. We simply search on the term “Cloud Computing” and the first entry happens to point to this Wikipedia page. For this stage of the experiment, we will take that page to be a reasonable representation of the current information about cloud computing.
- How do we know that this information is current? A look at the history of edits shows that it is being updated almost daily (this is one of the benefits of sources like Wikipedia)
- We will parse this page and find the top 20 most frequent bigrams (pairs of words). We do this using a simple python program using the Natural Language Tool Kit library (there are other methods of doing this as well).
- We pick a few of the more interesting terms. In the list below, the first column represents the term and the second column the number of times the term occurs in the document.
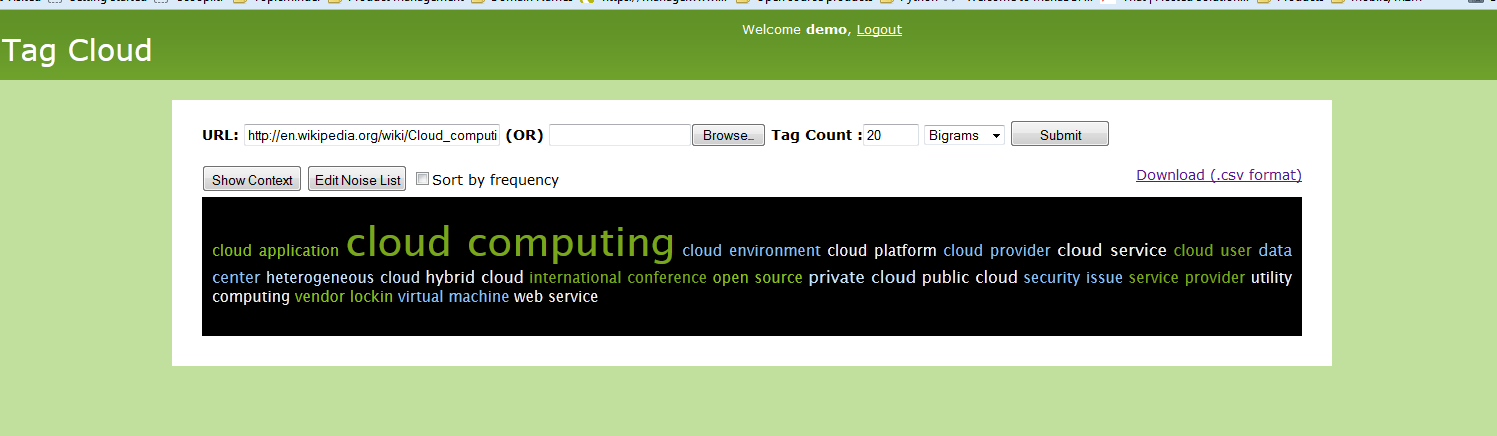
cloud computing 156 cloud services 14 public cloud 14 private cloud 13 hybrid cloud 10 cloud providers 8 cloud applications 7 cloud based 7 cloud cloud 7 cloud infrastructure 7 cloud service 7 category cloud 6 heterogeneous cloud 6 use cloud 6 cloud clients 5 cloud environment 5 cloud storage 5 cloud symbol 5 cloud user 5 data cloud 5 software cloud 5
Now we have a very crude version of the vocabulary on Cloud computing. This provides us a good starting point for further searches. Before we do that, we will eliminate some of the terms (like cloud cloud).
We can improve this process in several ways.
- We can look at more than one page or document. A good candidate is NIST’s Cloud Computing Definition document, which is listed as one of the references in the wikipedia page. There may be others. If we use multiple documents, we may use tf/idf (term frequency/inter document frequency) or some other metric.
- We can repeat the term frequency program to include trigrams (triple words like “cloud computing platforms”) and add them to the list.
- There are other (better) ways to get the terms and we will reserve that option for the future. A web search for “cloud terminology”, “cloud ontology” reveals some interesting sources like this one – a dictionary of cloud terms.
- Our quest, however, is to come up with simple methods of generating these terms ourselves. There are two reasons for doing this. One is that we may need to research topics that are not as popular as cloud computing for which the terminology may not exist. The second reason is that if we know how to automate and refine these terms, we can keep them updated as frequently as we want.
Meta:
If you want the (really crude) Python program I used to derive these terms, you can find it here.
Used another experimental tag cloud generator we built to visualize these tags.
Next step:
We will use the terms to find some relevant sources of information.