Mashup Camp starts in about a week’s time. In case you have not heard:
A mashup is a website or web application that uses content from more than one source to create a completely new service.
More information is here. Programmable Web does a great job of keeping track of mashups and the APIs (the backbone of any mashup). In addition it tracks trends in developing both APIs and mashups.
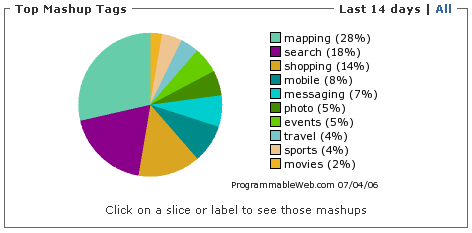
Here is a diagram that shows the top 10 mashup tags. The most popular one seems to be maps. The second most popular is Search. We will dig a little bit deeper into search mashups.

There are several types of search mashup. A broad classification includes:
- Business Finders
- Product Search (including book search)
- Real-estate search
- Celebrity Search
- City Search
- Social Search
Most of them are built with Google, Amazon, eBay, Yahoo etc. Combined with Google and Yahoo maps, many of these search mashups pinpoint resources on maps.
The kind of Search Mashups I have in mind are slightly different. These can be broadly divided into the following classes:
- Using popular Search Engine APIs (Google, Yahoo, MSN) vs using free search engines like Lucene
- Built as a pre-processor for search engines
- Provide some post processing capabilities of search results
- Tuned to customize/verticalize searches
Many of these features are designed to bring more contextual information to search and refine the results. I will expand on this in my future posts. I am really looking forward to a lot of interaction and interesting conversations during the mashup camp.
One thought on “Search Mashups”
Comments are closed.